Optimizing NP-Guard
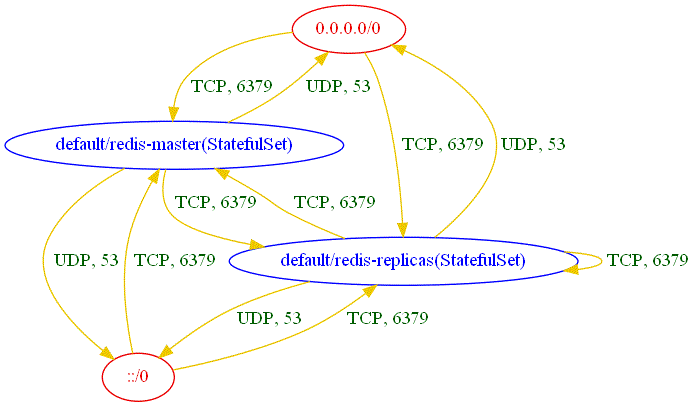
As part of my summer internship at IBM Research Israel, I worked on a project that was part of a larger open-source tool called NP-Guard. The tool is designed to help developers write more secure Kubernetes network policies and automate the error-prone process. NP-Guard achieves this by converting Kubernetes network policies and specifications into mixed string and integer product sets, and different tool functions are mapped to set operations such as emptiness check and computing the union or intersection between two sets. The tool’s set operations are computed using an in-house built engine.
My main focus during this project was on optimizing the tool’s performance by modifying the in-house engine. I explored two options to achieve this goal. The first option was to use the Z3 theorem prover instead of the in-house engine. The second option was to modify the in-house engine to use a more compact DAG-based (Directed Acyclic Graph) data structure instead of a tree-based data structure to represent the sets, which would allow for more efficient computation. The implementation of the new data structure was inspired by BDDs.
You can find more details about my project in the slides, and you can learn more about the larger NP-Guard tool on its website or its GitHub repository.